Side Project: URL Shortening service

前陣子在準備 System Design 時一直看到經典的短網址設計問題,直到近期比較有空決定自己實作一遍,同時把過程中遇到的重點記錄下來。
專案目標:
- 實現一個類似於 TinyURL 的短網址服務
- 練習概念驗證 (Proof of Concepts, POC)
短網址的目的?
- 確保網址長度能夠在任何平台/瀏覽器上正常發送
- 將原始網址替換成有識別度的別名
- 提高網址轉換成 QRCode 時的辨識準確度
短網址的運作原理
首先,我們只針對短網址服務的核心業務流程做分析:
從業務流程中能發想的問題點 (Functional Requirements):
- 短網址驗證的注意事項
- 短網址有效期限的設計考量
- 重新導向的設計考量
從系統層面延伸的問題發想 (Non-Functional Requirements):
- 服務的負載瓶頸?
- 短網址演算法的選擇?
- 業務場景中的資料讀寫比例?
- 服務監控指標的設計考量
預估系統負載
確定好核心業務後,下一步開始針對業務場景提出負載預估,每次看到大神等級的人都能逐一分析出不同面向的成本預估,而我做起來就像在雲開發 🫥
總之,接著開始吧
1. 使用場景
從上圖來看,相同性質的產品中以 tinyurl.com 的 1 億次月流量穩坐龍頭
我們假設短網址的讀寫比例為 100 : 1,換句話說每 1 條短網址平均會有 100 次的點擊量,因此以 tinyurl.com 而言,可以先整理出來的基本資訊有:
- 每個月大約會產生 100 萬筆短網址,以及後續的 1 億次的短網址跳轉請求
- 前者的 RPS (Requests Per Second) 約 1M URLs / (30 days * 24 hours * 3,600 seconds) ~=
0.4 URLs/s - 同理,後者的 RPS 約
40 URLs/s
峰值的計算參考八二法則,即一天中 80% 的流量會集中在 20% 的時間裡:
- 產生短網址的請求峰值約為 (1M URLs / 30 days * 80%) / (86,400 seconds * 20%) ~=
1.5 URLs/s - 同理,跳轉請求的峰值約為
150 URLs/s
2. 網路傳輸
實際在 tinyurl.com 使用 Chrome DevTools 分析可以得到:
- 每產生一筆短網址的封包傳輸量約為 1k bytes
- 每次跳轉請求封包傳輸量約為 500 bytes
沿用一開始計算出的流量可以得到:
- 產生短網址的網路傳輸量為 0.4 URLs * 1k bytes ~=
400 B/s- 峰值約為 1.5 URLs * 1k bytes ~=
1.5 KB/s
- 峰值約為 1.5 URLs * 1k bytes ~=
- 短網址跳轉為 40 URLs * 500 bytes ~=
20 KB/s- 峰值約為
75 KB/s
- 峰值約為
3. 資料儲存
我們以 response payload 的封包大小 600 bytes 為假設:
- 每一年總共會產生 1M URLs * 12 months ~=
12M URLs/year筆短網址 - 每一年資料儲存量為 12M URLs * 600 bytes ~=
7.2 GB
4. 資料快取
為了加快服務的響應速度,我們通常會將常用的資料保留在 server 上,在這裡就是短網址,一樣以八二法則為例,倘若我們希望保留近三個月的熱門網址查詢記錄,所需要的記憶體大小為:
- 1M URLs * 3 months * 600 bytes * 20% ~=
360 MB
有了上述這些參考資料後,在後續開發與測試上就能以更精確的數字帶入使用
產品原型規劃
prototype 的相關開發文件請直接瀏覽我的 GitHub Repo,包含:
- 核心功能技術文件、DB Schema、部署與啟動方式、整合測試、etc.
實驗結果
機器規格如下:
- 機器型號:MacBook Pro 14" 2021
- CPU:Apple M1 Pro
- RAM:32 GB
所有服務皆透過 Docker-compose 啟動,主要服務統一以下設定:
- e.g. TinyURL server、MySQL、Redis
- 詳細配置請見 deployment
| |
Locust
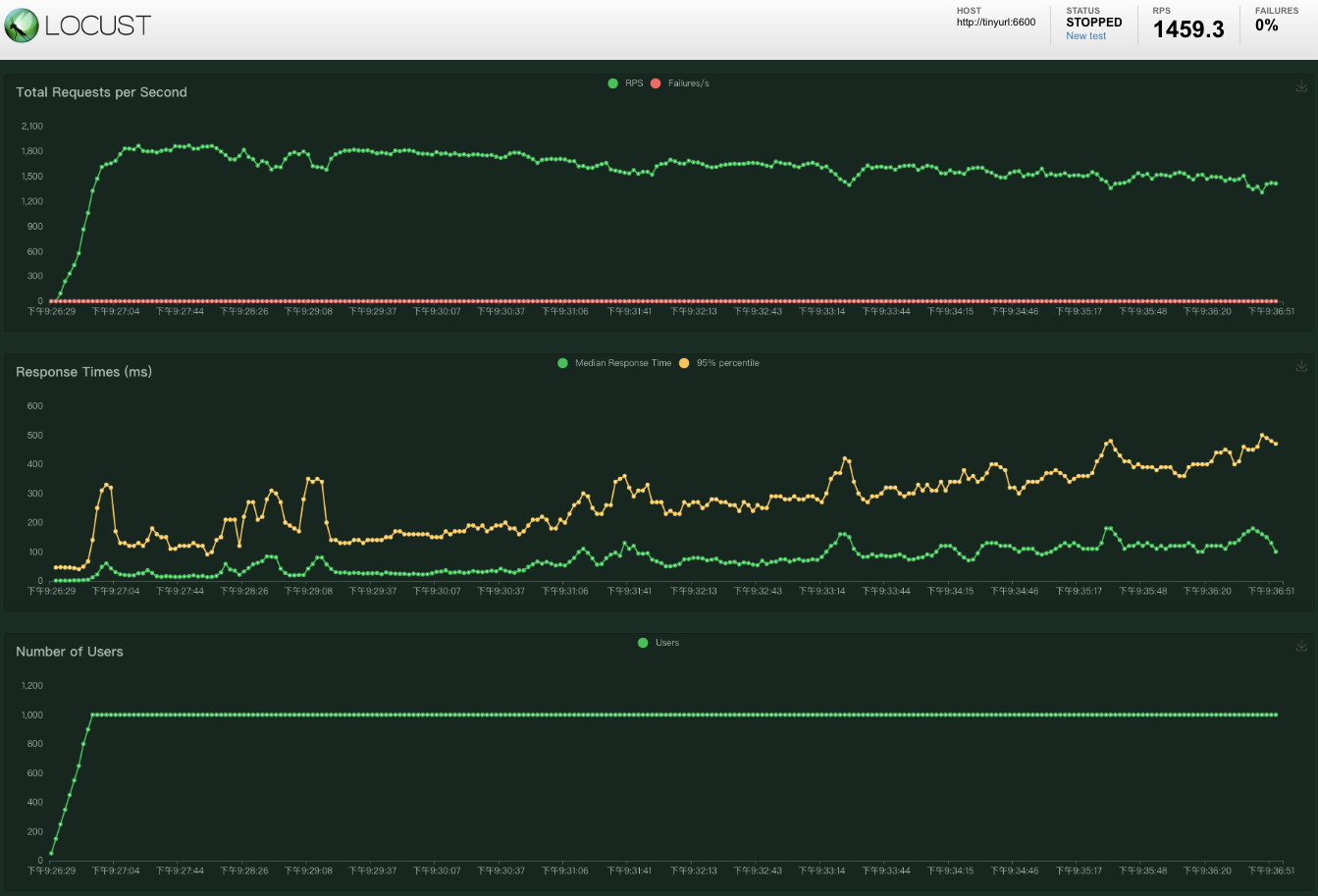
上圖是使用 locust.io 這套 Python 的壓測工具實測出來的結果,以 100 : 1 的讀寫請求模擬使用場景,RPS 平均落在 ~1460 左右
Grafana
Server
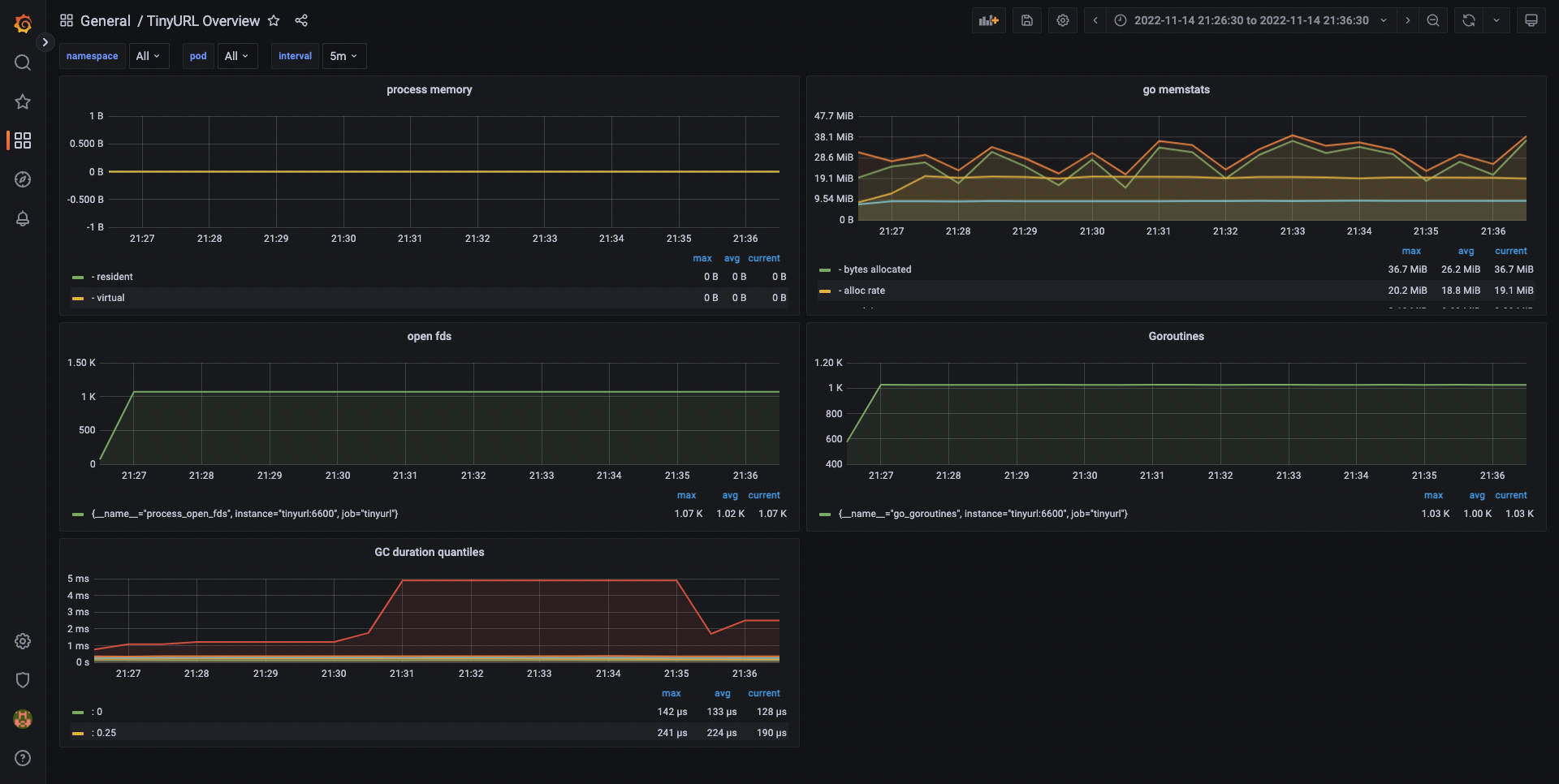
同一時間 Prometheus 對 Server 採集到的指標
MySQL
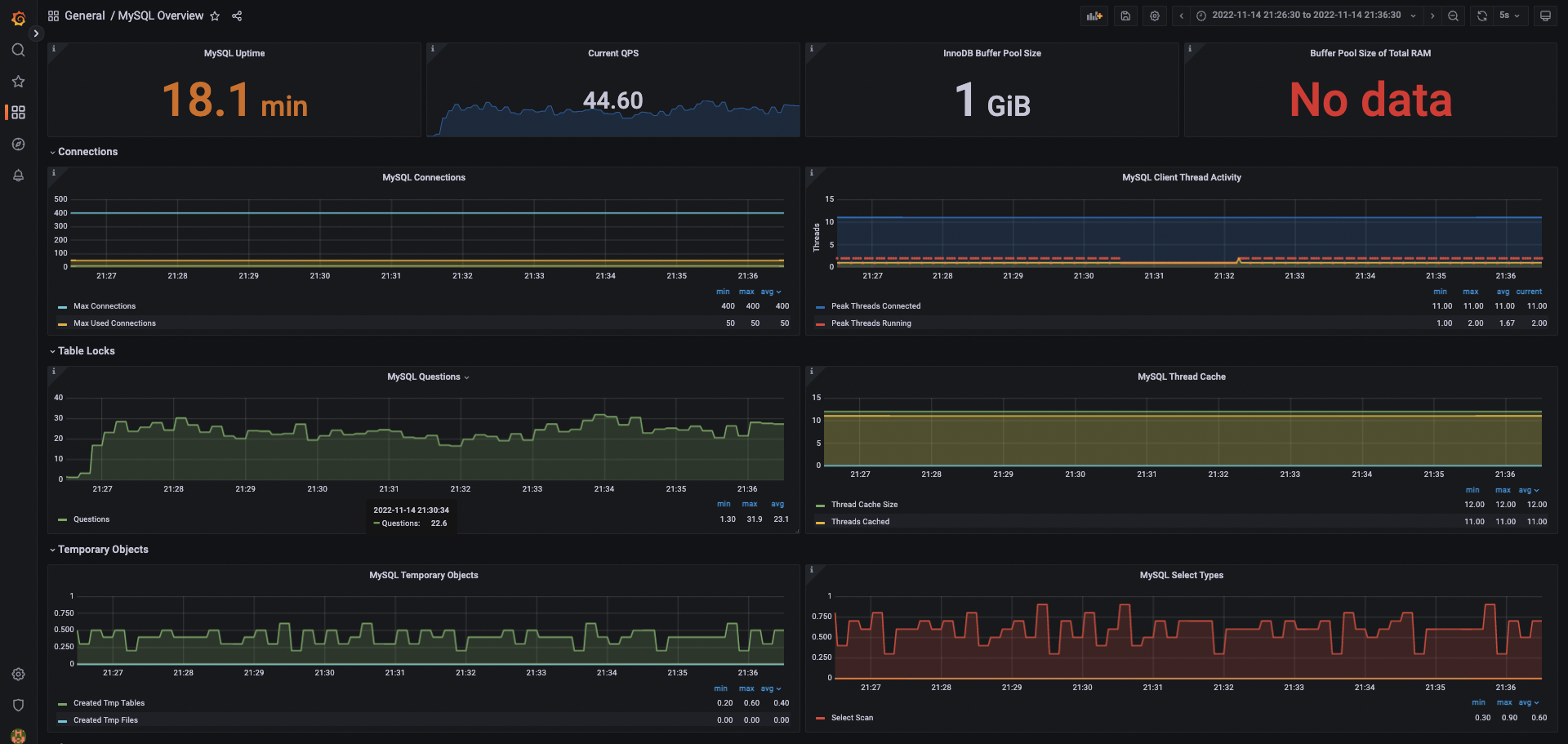
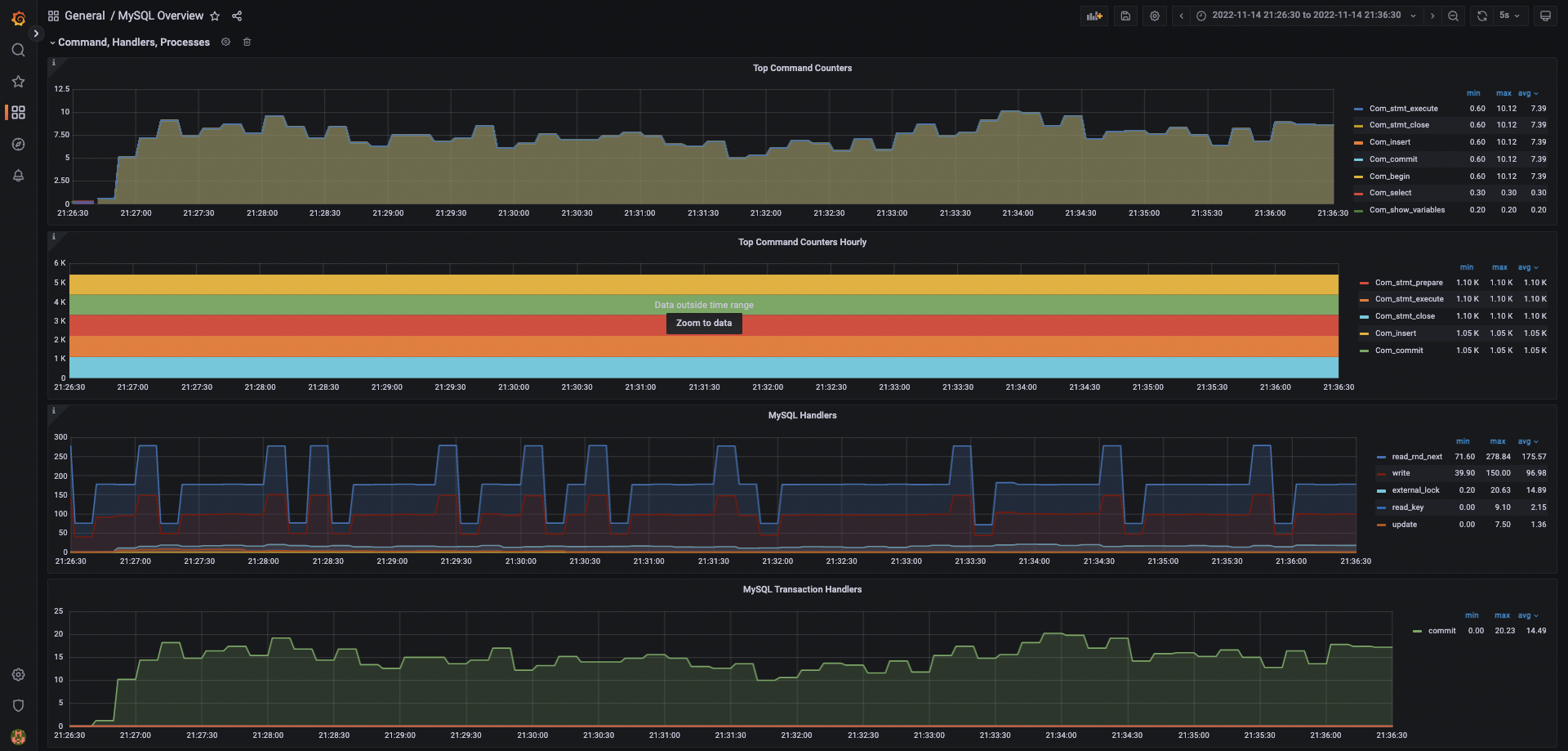
僅擷取 MySQL 的部分 metrics,可以發現 server 對 MySQL 的請求數並不高,QPS 僅有 40~50
Redis
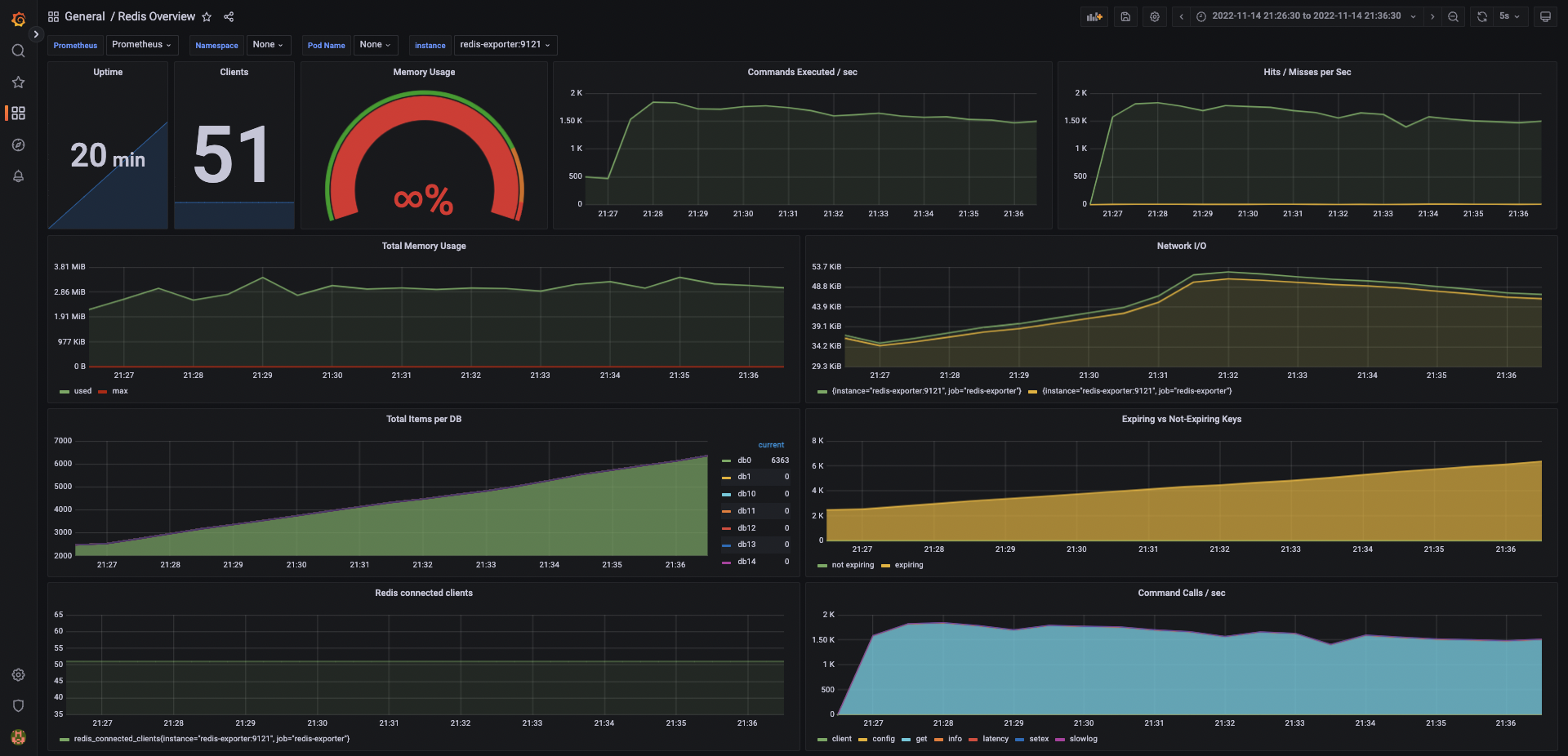
原因在於大部分的查詢都能在 Redis 處理完畢
更多的測試模擬可以從 python script 中找到,這裡就不逐一展開
有興趣的朋友可以下載我的 repo 後自行使用,過程中若有遇到問題也歡迎提供給我一起研究
技術筆記
MurmurHash3
針對 加密雜湊算法 與 非加密雜湊算法 之間的原理,我想留到下次在針對這個主題做完整的筆記
這裡只列出 MurmurHash3 與其他雜湊算法的 10 萬次壓測結果比較
後記
這次的 side project 讓我釐清了很多當時在看 System Design 時不清楚的設計目的,但也因為這次主要是為了練習 POC,因此在實作過程中省略了不少細節考量:
- e.g. 跨資料庫時的一致性保證、災難復原 & 故障轉移機制、限流機制、etc.
針對 POC 來說,這次主要練習了從零到一過程中的 需求分析 ➜ 可行性評估 ➜ 撰寫開發文件 ➜ 需求開發 ➜ 釋出 protype ➜ 壓力測試 & 系統監控
在工作中除非能夠從頭參與項目誕生,否則上述流程通常在初期就會決定完畢,後期大部分時間都是根據現有框架繼續開發需求或小規模重構/優化
隨著專案日漸龐大也越難有大規模改造的機會,因此這次的 side project 是個不錯的練習,可以補足平常較少接觸到的部分,之後有空時再來挑選其他主題繼續練習 POC